
线上一台服务器告警,磁盘利用率 disk.util > 90,并持续告警。
登录该服务器后通过iostat -x 1 10查看了相关磁盘使用信息。相关截图如下:
|
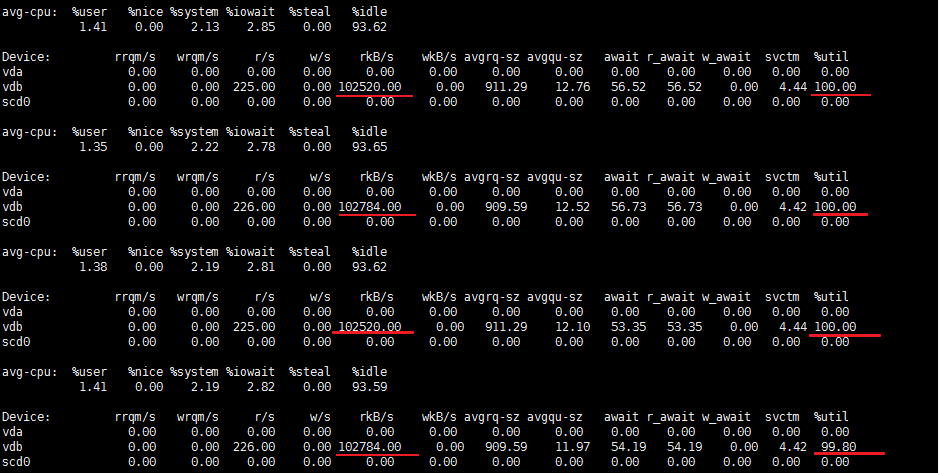
由上图可知,vdb磁盘的 %util【IO】几乎都在100%,原因是频繁的读取数据造成的。
其他字段说明
Device:设备名称
tps:每秒的IO读、写请求数量,多个逻辑请求可以组合成对设备的单个I/O请求。
Blk_read/s (kB_read/s, MB_read/s):从设备读取的数据量,以每秒若干块(千字节、兆字节)表示。块相当于扇区,因此块大小为512字节。
Blk_wrtn/s (kB_wrtn/s, MB_wrtn/s):写入设备的数据量,以每秒若干块(千字节、兆字节)表示。块相当于扇区,因此块大小为512字节。
Blk_read (kB_read, MB_read):读取块的总数(千字节、兆字节)。
Blk_wrtn (kB_wrtn, MB_wrtn):写入块的总数(千字节,兆字节)。
rrqm/s:每秒合并到设备的读请求数。即delta(rmerge)/s
wrqm/s:每秒合并到设备的写入请求数。即delta(wmerge)/s
r/s:每秒完成的读I/O设备次数。即delta(rio)/s
w/s:每秒完成的写I/0设备次数。即delta(wio)/s
rsec/s (rkB/s, rMB/s):每秒读取设备的扇区数(千字节、兆字节)。每扇区大小为512字节
wsec/s (wkB/s, wMB/s):每秒写入设备的扇区数(千字节、兆字节)。每扇区大小为512字节
avgrq-sz:平均每次设备I/O操作的数据量(扇区为单位)。即delta(rsec+wsec)/delta(rio+wio)
avgqu-sz:平均每次发送给设备的I/O队列长度。
await:平均每次IO请求等待时间。(包括等待队列时间和处理时间,毫秒为单位)
r_await:平均每次IO读请求等待时间。(包括等待队列时间和处理时间,毫秒为单位)
w_await:平均每次IO写请求等待时间。(包括等待队列时间和处理时间,毫秒为单位)
svctm:平均每次设备I/O操作的处理时间(毫秒)。警告!不要再相信这个字段值,这个字段将在将来的sysstat版本中删除。
%util:一秒中有百分之多少的时间用于I/O操作,或者说一秒中有多少时间I/O队列是非空的。当该值接近100%时,设备饱和发生。
找到 IO 占用高的进程
通过 iotop 命令
如果没有该命令,请通过yum install iotop进行安装。
# iotop -oP

通过这个命令可以看见比较详细信息
如:进程号,磁盘读取量,磁盘写入量,IO百分比,涉及到的命令是什么「两个都是 grep 命令造成的IO读取量大」。
通过 pidstat 命令
# 命令的含义:展示I/O统计,每秒更新一次 # pidstat -d 1
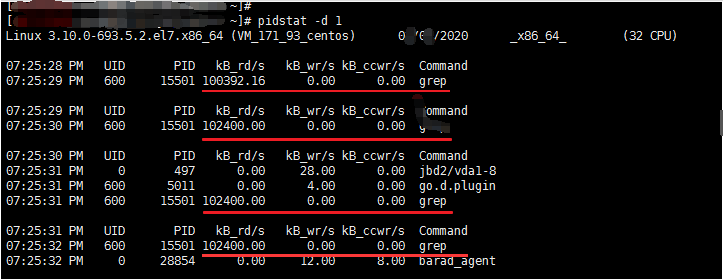
可见其中 grep 命令占用了大量的读IO,之后可根据 PID 查看相关进程信息。
说明:本图与上图的PID不同,原因是上图涉及的进程执行完了,本图是之后执行产生的进程【都执行的同一个脚本】。
以上所述是给大家介绍的Linux 查看磁盘IO并找出占用IO读写很高的进程方便解决

Powered by rrcnzz.com
©2019 - 2026 人人站长网
您的IP:216.73.216.169,2026-06-25 13:07:28,Processed in 0.00832 second(s).

